Motivation
TL/DR; inter-device interoperability of hardware modules (sensors, actuators, interfaces) could enable a rapid growth of Open Source Hardware capability, expanding beyond single-microcontroller projects and easing the burden of integration between specialized contributions. OSAP is an experimental framework / utility for systems assembly tools that could enable such an ecosystem.
OSAP at OSHWA
I launched this project at OSHWA in 2022, in the talk below, I explain OSAP’s motivation, approach, and discuss a few use cases.
Modular Peer Production
Modular system architectures are key enablers for open source communities; they allow individuals to make piecewise contributions to a commons of modular building blocks which are then readily re-assembled into new applications1. This pattern is identfied by many theorists who aim to understand how open source software development models can build massively complex systems with collective, uncoordinated labour2.
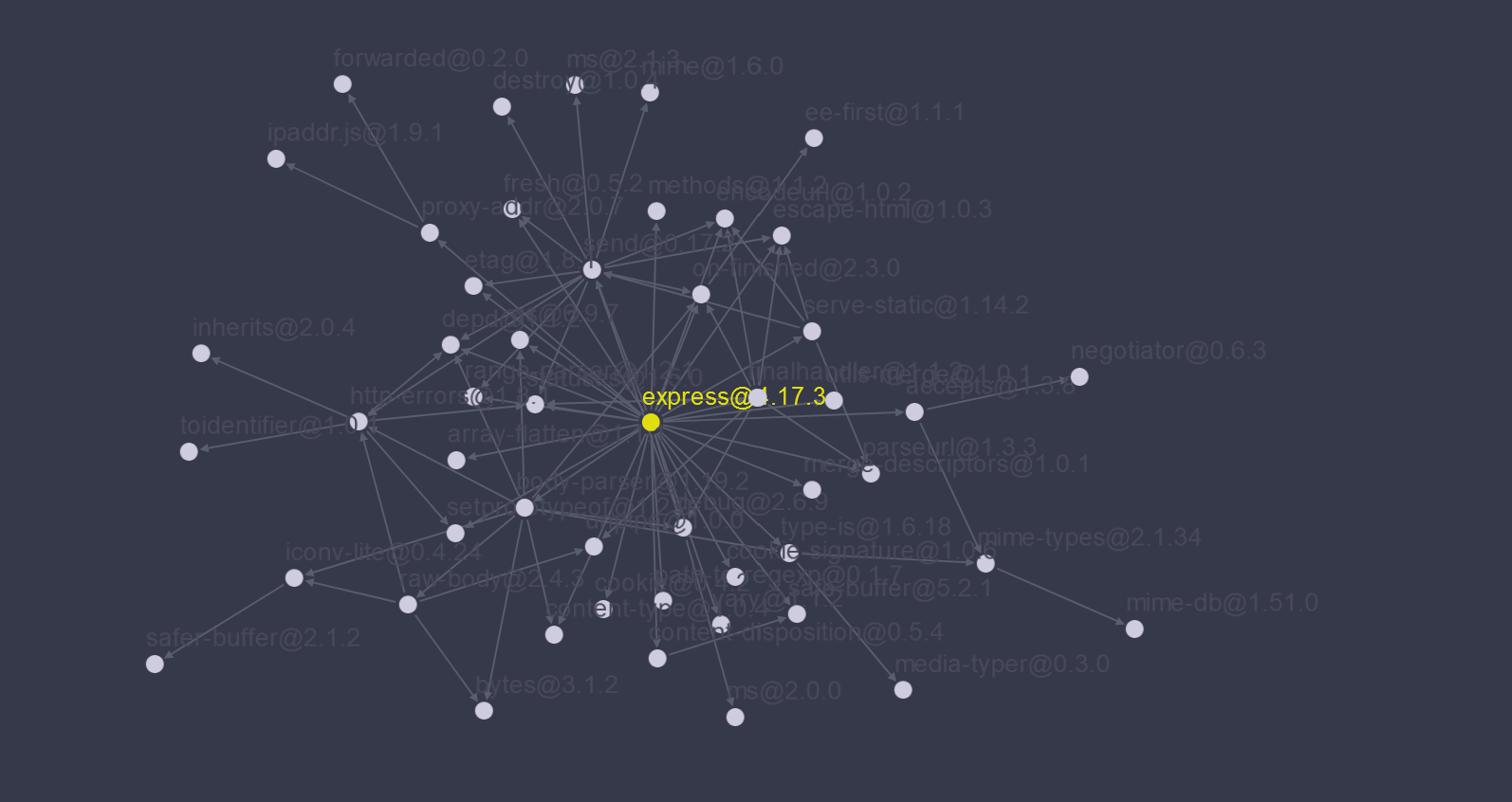 This is express (a nodejs server package), with code dependencies visualized on this neat tool. Express is "minimalist" but uses a total of 50 dependencies connected on 83 edges, and the collected labour of 107 individuals.
This is express (a nodejs server package), with code dependencies visualized on this neat tool. Express is "minimalist" but uses a total of 50 dependencies connected on 83 edges, and the collected labour of 107 individuals. Burden of Integration
When comparing Open Source Software (OSS, which is thriving) with Open Source Hardware (OSHW, emerging), most folks look first to the differences in cost - hardware having nonzero incremental (and larger fixed) costs than software (which has “zero” and less cost respectively). This is an important distinction, but we should also think about the intellectual burden3 imposed on developers when they choose to use contributions made by others within their open communities. Levels of intellectual burden largely vary depending on the performance of the systems assembly architectures used in these communities.
For example, the abstraction of software functionality into re-useable, easily understood modules is undertaken as a kind of pathology in programming circles: all codes should be abstracted from application-specificness, semantically elegant, and portable. This is the way. The boundaries on software modules are also easily identified: we have packages (and package managers) that contain software objects (or groups of them with shared function) which can each be used via invocation of an API4. APIs can be easily described to other programmers because they are accessed using a representation that is common - the function call!
The result is that the burden on software developers for integrating others’ contributions is very small: programmers need to understand very little about one another’s code in order to successfully put it to use. This is partially because of a regularization in API documentation, but also due to the performance of our compilers and scripting languages that we use to assemble trees of dependencies and libraries into standalone applications - i.e. when we #include handfuls of libraries, gcc builds them into a single executable. It’s such a fluid little miracle that we hardly even think of it as systems assembly, but that’s really what’s going on. Same can be said for npm install or homebrew, etc etc.
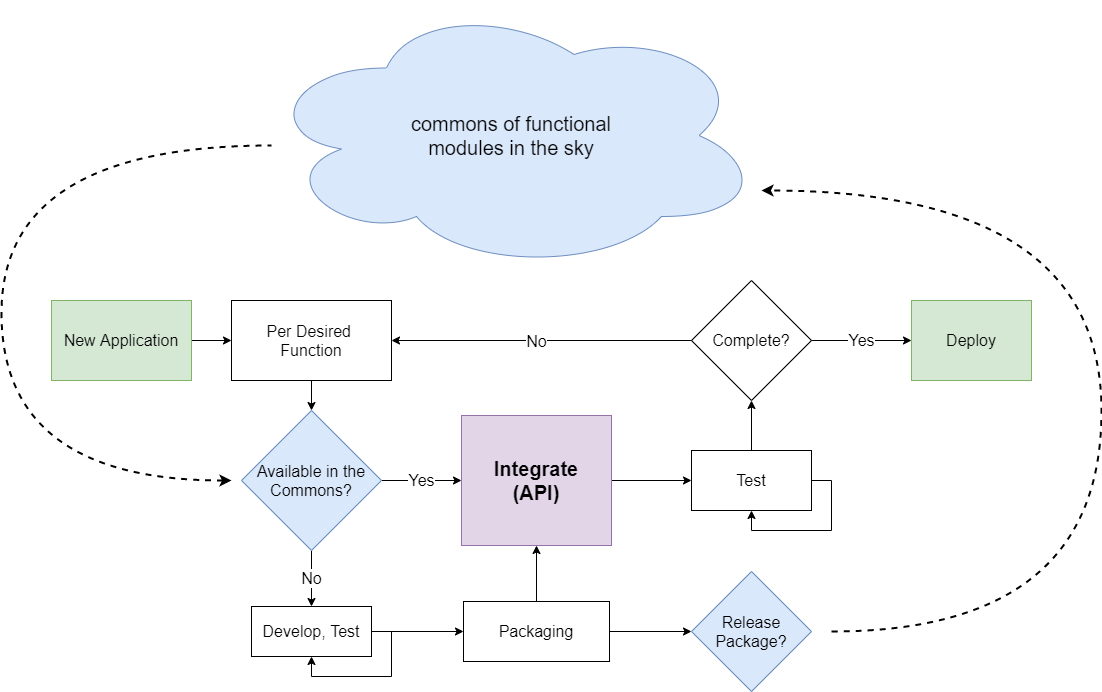 This is a reduction of how developers in Open Software often write code: we look for functional modules in places like PIP (python package manager) and NPM (node.js package manager), which many theorists would call "knowledge commons" and then integrate those into our application-specific code.
This is a reduction of how developers in Open Software often write code: we look for functional modules in places like PIP (python package manager) and NPM (node.js package manager), which many theorists would call "knowledge commons" and then integrate those into our application-specific code. Low integration burdens mean that developers in a community are more likely to build new functionality rather than re-hashing solved problems in new contexts; if we go about making a new application and find that 90% of it can be rapidly re-assembled from functional modules available to us in an open source commons, we have more time to build new functionality onto that system. We are also more likely to contribute our newly developed functionality back to the commons5.
If, however, integration burdens are high and we need to understand how others’ contributions work in order to integrate them in our project, we are more likely to use all of our available time simply re-creating what the community already knows how to accomplish and are less likely to develop new capabilities… this all means that the systems assembly architectures we use in an open development community are critical determinants for the growth of a commons of functional modules, and on the ability of the community to build awesome stuff.
Scaling in Software vs Hardware
Modularity in hardware systems is harder to come by than it is in software systems; we are beguiled by a heterogeneity of microcontrollers, compilers, programming protocols, data link layers, etc. Indeed the development of hardware includes the entire field of software development as a subset, including the messy genre of firmware development. And then it also includes circuits, sensors, actuators, ICs, etc.
Perhaps as a result, OSHW seems to have settled into a local minima where folks release development boards for microcontrollers, breakout boards for ICs, and Arduino libraries to glue them together in code6. This ecosystem is modular in some regards, but it falters in a few important aspects.
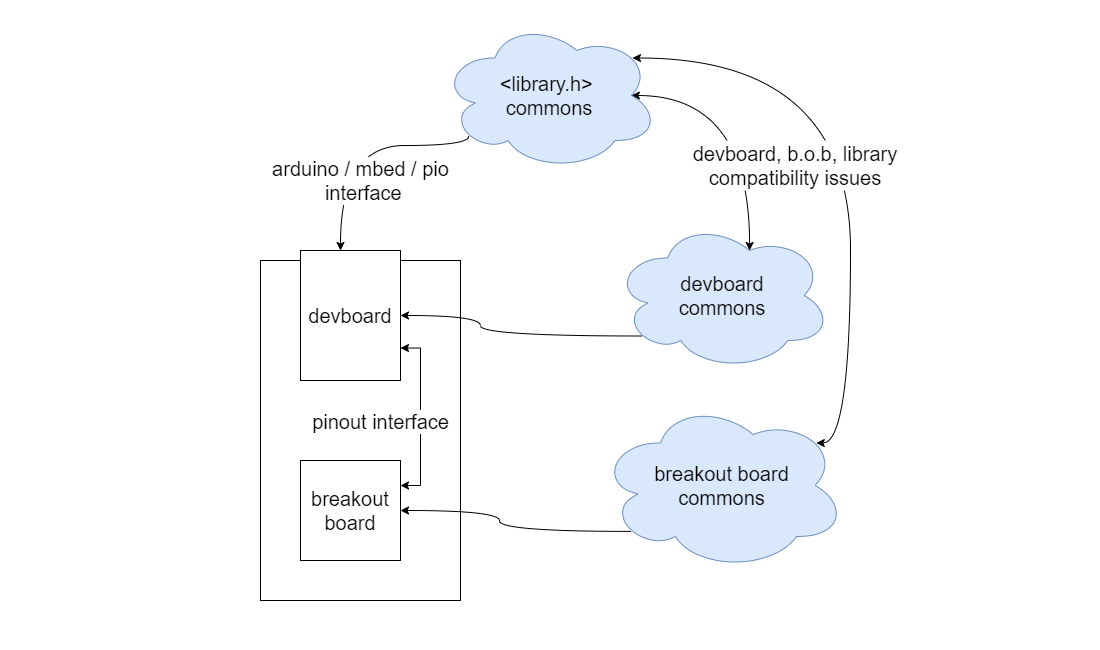 The "commons" in OSHW are more difficult to distinguish than those in OSS, perhaps because the ways that hardwares integrate into other hardwares are so varied. With something like OSAP, we could contain a lot of these complexities in protocol and work towards modular interoperability based on building-blocks of function, rather than building-blocks of hardware.
The "commons" in OSHW are more difficult to distinguish than those in OSS, perhaps because the ways that hardwares integrate into other hardwares are so varied. With something like OSAP, we could contain a lot of these complexities in protocol and work towards modular interoperability based on building-blocks of function, rather than building-blocks of hardware. I’ll take for granted that the reader has at some point run out of microcontroller pins, or has been unable to find an arduino library for their project which was compatible with their particular microcontroller, or has been confounded by a missing or errant pinout7, etc. We know that the burden of integration can be high; this is the first issue with our current approach.
The second, perhaps more important issue is simply that it fails to scale beyond projects of microcontroller-count = 1. The power of modular systems is their ability to be recombined at scale, i.e. in the express package diagrammed above (self advertised as ‘minimal’) which uses 50 (!) dependencies. OSHW should aspire to this level of modularity: instead it seems that there is much re-hashing of the same projects, the same development boards and kits, with little added in the way of radically new functionality, and small scaling in the overall complexity of systems built. We need to leave the single-board world behind, and progress to wickedly scalable networked systems. We need some systems assembly architecture with which to do it if we are ever to hope that our circuits might talk to one another and work together in a decentralized manner, in much the same way as we might hope to work with one another.
Challenges in Network Assembly
A networking approach allows us to put lots of different microcontrollers together into a single system - and it also allows us to use heterogeneous computing components. This means that we can leave the mess of microcontroller particularity8 in the compiler and then standardize around message passing. It also means that we can describe hardware systems and larger computing systems with one representation; i.e. many Open Source Hardware projects anyways have some UI or interface element - often a desktop application that communicates to a device using a serial port or bluetooth, etc. In embracing networking as a systems assembly approach, these scripts become first-class system members; network approaches can be polyglot9, so UI elements or desktop python scripts become just another node in a large graph of hardware and software modules.
There are of course challenges to this approach, not the first of which is simply establishing some connectivity: do we have to pick standardized connectors? Do we need to use fancy link layers, like TCP/IP? Will we run out of microcontroller memory? How do we describe, render and edit messy networked systems? How do we address things? What about differences in performance - can my ATTINY play nicely with my Teensy, and that with my Raspberry Pi? I think that OSAP has answers to many of these questions - this is why I built it - so if you’re still here, carry on and read about the approach;
What’s Changed
I should also address what’s new in the world that makes this project possible today, where it may have had a more difficult time emerging a few years ago.
The first reason, I think, is that the OSHW community has reached a level of maturity where folks are ready to scale their projects beyond the breadboard. This is in no small part due to all of the amazing work that has gone on in the community and in nodes like Arduino, Adafruit, Sparkfun, Hackaday, etc - I suspect readers here are well immersed and know what I’m talking about. The youtube ecosystem of makers-making-stuff, circuit design tutorials, programming education, etc etc, means that almost anyone who wants to start learning how to develop hardware can do so. Dev board costs continue to drop, custom PCB fab is getting easier, and PCB design softwares like Eagle are being designed around accessibility, as is the open source KiCAD becoming a powerhouse in its own right. I worry a little bit about the chip shortage’s crunch on OSHW growth, but I also think that OSAP is perhaps a great answer to this problem, allowing us to side-step the complexity of cross-microcontroller integration by leaning on network rather than compiler config. We will see.
There has also been a lot of growth in IoT, and so network connectivity is being pushed further down into microcontrollers available on market. OSAP can run on a link as simple as a UART port, but growth in IoT means also that community members are more likely to be practiced in the implementation of networking codes. There is a palpable ‘vibe’10 that folks want to see networked modularity: looking again at QWIIC and Stemma, also projects like Klipper and the inclusion of CAN busses on all kinds of new boards… also Ethernet on Teensys, etc etc, it’s coming.
Microcontrollers have also been on a positive trend lately, and that’s just dirty old moore’s law in a lot of ways… also a consumer (and auto) market that has driven for more-smarts-everywhere. The SAMD51 is a kind of “middle-range” chip these days, but would’ve been a powerhouse a few years ago. Teensy 4.x series can be overclocked to a near-mythical GHz. Our ability to do some medium-hefty computing at the edges of our systems is emerging, and we will need computing frameworks to coordinate that.
There’s also the perrenial desire for modular CNC, an application that I have written much of OSAP to handle. Machines are about the right level of complexity with which to develop weird new controllers, and they also push performance limits what with their realtime-ness and all. CNC is also rewarding enough to drive us to develop something that works beautifully: watching an endmill slice your part out of a hunk of material is never not-satisfying.
So that’s it; (1) I think the OSHW community is ready for it and wants to see it, (2) IoT is happening, (3) we have lots of compute at the edges (and great micros for small $) and no strong multi-computer frameworks with which to coordinate them, and (4) - a bit of an aside - truly modular CNC demands network control.
Footnotes
-
Nadia Egbhal’s book Working in Public: the making and maintenance of open source software does very well to explain this phenomenon. In particular, she notes, the main users of open source software are other developers - not end users - for whom application specific code is produced (from OSS modules) and sold to, normally as a service. As such, it seems better to understand open source software as a collection of useful modules - a kind of toolkit, or a series of building blocks - from which developers can rapidly build new highly specific products with. The collection of these building blocks, then, she calls a commons in the style of Elinor Ostrom. ↩
-
I would cite here Coase’s Penguin (Benkler, 2002), Democratizing Innovation (von Hippel, 2005), The Simple Economics of Open Source (Lerner and Tirole, 2000), Exploring the Structure of Complex Software Designs (MacCormack et al, 2006), and (Egbhal, 2020) from above. Each studied the production of open source software, and each identified modularity, interoperability, and fine granularity of contributions as prime drivers for the success of OSS. ↩
-
The notion of intellectual burden is another recurring theme when we read economists / theorists discussing peer production: we can think of it as a kind of friction between the existence of an open source component and its successful use. This is also an interesting way to think about open source in general: i.e. the release of an executable file and the release of source code into the open are both functionally similar if we ignore intellectual burden: they both do the same thing. However, one is explainable, and understandable (and so, useful for other things) by others. This notion is aligned with a drive in the OSHW community for better documentation as well: that’s a desire for lower intellectual burden, as we go about using one another’s works. ↩
-
This is not entirely true - many codes present themselves as services that are accessed via network links, i.e. REST APIs. But the point is likely understood: methods for assembling code modules into large applications is well traversed territory. And anyways the network-accessed software API strategies play well into our themes here. ↩
-
This part makes a lot of sense in existing economic frameworks, which are normally based on making sense of resource-constrained systems. First we suppose that each individual open source contributor has limited time. Suppose a particular individual wants to make
Xproject, which has componentsA,B,C, and D… SupposingA,B,Cexist in this commons of freely available resources, the individual has only to use their time integrating these components to work in their new application. This is where burden of integration comes in: if our systems assembly architectures are good, the burden will be low (integration is easy, takes little time and effort). If it is high, most of the individual’s time will be allocated to integration of existing solutions: reading API docs, perhaps rewriting some code for compatibility, or understanding circuit diagrams, pinouts and performance ranges. All of this takes time and intellectual resource: if our individual here is using a Model Predictive Control package contributed by a PhD in the topic, we shouldn’t expect that they understand how it works, even if they can read the code. As a result, no time is left for the development of componentD- the new bits, that have a chance of expanding what is possible to make with the resources available in the commons - and the individual’s likelihood of having extra time with which to publishDback into the commons is lower still. It’s also worth considering the acquisition ofA,B,Cfrom separate projects: for example ifA,Bare functional components of projectYandCis a component of projectW- we need good systems assembly architectures here as well, such thatA,Bcan be excised fromYwithout breaking, likewiseCfromW- and then thatA,Bshould be successfully combined withC- and with new developmentD. This is all the kind of stuff that happens without much friction in software, but with heavy losses in hardware. ↩ -
I need to acknowledge that I’m being reductionist again. There’s been a huge amount of work towards modularity in OSHW, especially of course from Arduino and firms like Adafruit and Sparkfun, who have both recently released the hinting-towards-modularity Stemma and QWIIK platforms. Compiler-side projects like PlatformIO are also making strides, and its worth a nod at platforms like Duet3D with their GPIO expansion ports, as well as the whole notion of “shields” etc. ↩
-
For evidence of this frustration, see the emergence of Adafruit’s Stemma or Sparkfun’s qwiic, which both aim to delete wiring complexity by putting everything on an I2C bus w/ a common ‘standard’ connector. ↩
-
I’m thinking in particular about how particular firmwares compile for particular microcontroller peripherals; these are the structures that actually interface between a microcontrollers’ code and the physical world: i.e. we use peripherals to set pin voltages or read data on communication links. They’re difficult to abstract because they lie in fixed memory locations that are different in any given microcontroller, and their functionality (and availability) also varies wildly from micro-to-micro. Arduino’s core value is in abstracting the complexities of these things away, but ground truths are often difficult to truly escape. ↩
-
Just a fun way to say: we can write each component of the network in a different language, so long as each speaks the same protocol at the end of the day. ↩
-
I know this section is totally un-academic. I’ll come back to it with more rigor in the future. ↩